
Med hjälp av artificiell intelligens har Google Assistant nu fått en talsyntes som låter läskigt naturtrogen.
För ett drygt år sedan presenterades WaveNet av Googleägda DeepMind. Det är ett djupt neuralt nätverk (DNN) som från grunden kan skapa mänskligt tal som låter betydligt mer naturtroget än dagens bästa talsynteser. Redan då lät det mycket bra, trots att det handlade om en forskningsprototyp. Den stora beräkningskraft som krävdes gjorde dock att WaveNet inte lämpade sig särskilt bra för att användas i konsumentprodukter såsom smartphones och smarthögtalare som Google Home. De senaste 12 månaderna har dock DeepMinds ingenjörer optimerat WaveNet rejält.
Den nya versionen av WaveNet är hela 1.000 gånger snabbare och spottar dessutom ur sig syntetiskt tal av ännu högre kvalitet. Nu meddelar DeepMind att denna uppdaterade version av WaveNet har implementeras i Google Assistant över samtliga plattformar för att generera talsynteserna för de amerikanska och japanska rösterna. På länken här under kan ni själva jämföra hur de (före detta) bästa talsynteserna idag låter jämfört med de nya WaveNet-baserade.
Lyssna på några exempel av den nya talsyntesen här
WaveNet lär sig imitera naturligt tal genom att lyssna på flera timmars inspelat mänskligt tal och slutresultatet blir väldigt övertygande med detaljer som läpp- och andningsljud som genereras i det syntetiska talet. Med WaveNet blir det även enklare att få till olika intonationer jämfört med traditionella talsyntesmodeller.
Det syntetiska tal som tidigare tog 20 sekunder att generera tar efter DeepMinds optimering av WaveNet bara en sekund och är av högre kvalitet. Ett annat sätt att mäta det är att det nu bara tar 50 millisekunder att generera en sekund av syntetiskt tal. Ljudkvalitetsmässigt innebär nya WaveNet också en förbättring med 24.000 samplingar/sekund i 16-bit istället för 16.000 samplingar/sekund i 8-bit.
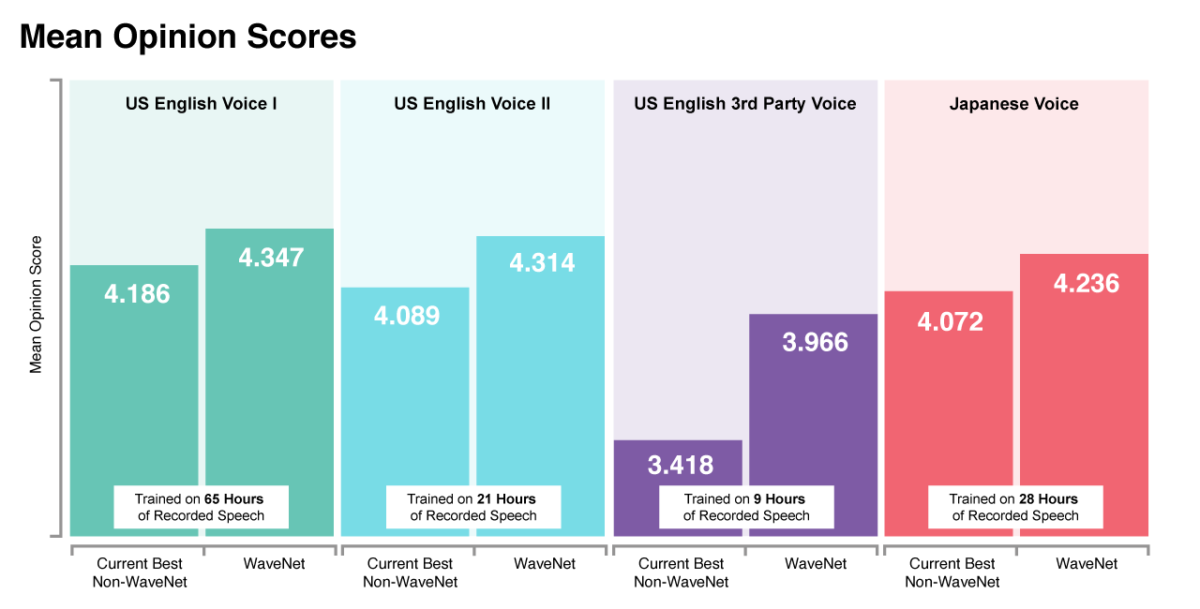
Man har låtit testpersoner lyssna på den nya WaveNet-talsyntesen för att avgöra hur naturligt den låter. ”US English Voice I” fick 4,347 MOS-poäng (Mean Opinion Score) på en skala från 1-5. Inte ens äkta mänskligt tal når dock 5,0 på denna skala utan ligger på 4,667, enligt DeepMind. Som jämförelse fick den bästa icke-WaveNet-talsyntesen av idag en MOS-poäng på 4,186.
”Vi tror att detta bara är början för WaveNet och vi är förväntansfulla över möjligheterna som styrkan i ett röstgränssnitt nu kan låsa upp för alla världens språk”, skriver DeepMind avslutningsvis.